
之前 rushcheyo 哥哥稍微修了一下题解的格式,所以公开的有点晚了,非常抱歉。
之前有人问我为啥出题人只有一个人,其实是因为出题人的确只有 command_block 一个人。六道题都是他一个人出的造的(虽然 D 题后来发生了一些事故,管理员们改了一波重造了题),非常感谢他愿意来 UOJ 举办这场比赛。
以及 Goodbye Gengzi 现在还缺题,欢迎各位小伙伴来投题啊~
多线程计算
from command_block,标程、数据 by command_block,题解 by rushcheyo
整个过程中一共会产生
定理:
证明可以在很多地方找到。
一个有
算法一
暴力枚举亮灯排列,然后模拟亮灯过程即可。
复杂度
算法二
由于对称性,一个节能态的贡献只与其亮起的处理器数
由于不同的节能态是独立的,不妨考虑
于是我们获得了一个多项式时间的做法!期望得分:
算法三
可以发现上面的计算实际上分为两步:先固定下
复杂度
算法四
将组合数用
二维 FFT 太高级了我不会怎么办!实际上第一部分的两维是独立的。具体的,我们记录数组
算法五
from EntropyIncreaser
第二步其实是可以线性时间解决的。
只需解决代价为
表示为积分
由 Beta 积分展开:
光伏元件
from command_block,数据、标程、题解 by command_block
算法一
暴力枚举所有可能的放置方案。
复杂度
算法二
解决保证
这里要求第
考虑使用带有上下界的网络流来求解。
把行和列分别用点表示,对于位置
一定为空:不连边。
一定有元件 :
可以改变,且初始时为空位:
可以改变,且初始时为元件:
如何限制行和列的流量相同呢?
可以发现,行的流量是流出的,列的流量是流入的,可以使用循环流的思路来限制,让列
求循环可行流即可。结合算法一,期望得分
算法三
解决保证
此时要考虑费用的限制,使用最小费用循环可行流。
一定为空 : 不连边。
一定为元件 :
可以改变,且初始时为空位 :
可以改变,且初始时为元件 :
图中可能有负环,实现时需要使用一些技巧。
结合算法一,期望得分:
算法四
解决原问题。
把中间的“反向”边改成这样的设计。
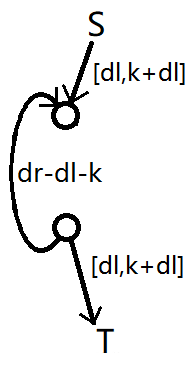
不难发现,由于上下边的下界均为
只需证明
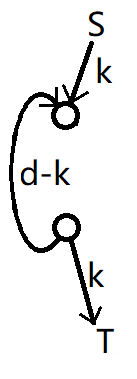
假设上方的流量为
那么上点的流量为
显然
反过来,若给出一组合法的点流量
若
由于
若
余下流量为
期望得分:
关于费用流的实现
本题的费用流建图点数为
若采用一般的 Edmonds-Karp 费用流,复杂度瓶颈为
服务器调度
from command_block,数据、标程、题解 by command_block
算法一
我会暴力!期望得分:
算法二
不难发现,修改时只会影响
复杂度
算法三
解决无修改的子问题。
先求出每组点集的直径,那么对于一条直径
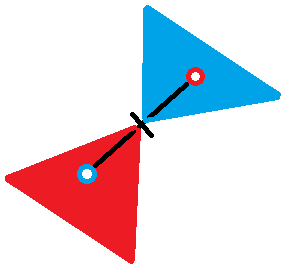
上图中,红色端点是
现在,我们要给红色区域的每个点加上到蓝点的距离,给蓝色区域加上到红点的距离。
观察树上两点距离公式:
不难发现,两个区域的分界边,就在直径的带权中点处,设其为
红色区域的点
蓝色区域就不是一颗完整的子树了,点
如果在
上述操作都可以用树上差分来解决,注意要特判某种区域只有一个点的情况。
复杂度
算法四
解决总是询问所有点延时总和的子问题。
考虑如何动态维护直径,众所周知点集直径是可以合并的,那么可以对每种颜色分别开一棵线段树来维护。为了降低时间,下面需要用到询问
对于每条点集直径,记录下其对答案的贡献,若发生变化重新计算即可,一次修改只会重新计算
现在,我们只需要计算每条直径对整棵树的贡献:
子树加,只需要预处理子树大小。
在
设
考虑
结合算法二,期望得分:
算法五
解决原问题。
在上面提及的两种贡献中,子树加使用下标为 dfs 序线段树即可处理,重点在第二类贡献难以计算。考虑一个子树的第二类贡献,如图 :
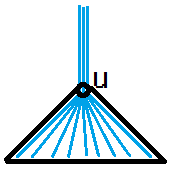
伸出框外的是
考虑如何求出
复杂度
打击复读
from command_block,数据 by skip2004,标程、题解 by mayaohua。
算法一
我会暴力枚举!
直接计算出每个本质不同子串的复读程度,这里可能需要字符串哈希。
修改操作只会修改
时间复杂度为
对于 subtask 2 来说,由于数据随机,所以期望长度
时间复杂度为
算法二
我会后缀树/后缀自动机!
显然若两个子串相同,它们的
用 SAM 建出反串后缀树,然后尝试统计答案。
考虑反串后缀树上的节点
在数据随机的情况下,
结合算法一可以通过 subtask 1~2,期望得分
算法三
我会分块 FFT!
上面计算的式子里面,
我们考虑到
时间复杂度为
对于 subtask 3,由于
结合算法一可以通过 subtask 1~3,期望得分
算法四
from command_block
我不会分块 FFT,但我会分析性质!
考虑分析一下
引理:对于串
这个是 the periodicity lemma 的直接推论。
那么我们考虑对原串分块。取一个块大小
这样总复杂度为
直接实现空间复杂度也是
算法五
from ezoilearner
扔掉分块的想法,重新考虑我们要计算的东西:
那么我们考虑直接重新建出正串的后缀树(相当于建出反串的 SAM),在上面定位出
如果我们要支持修改,这也是简单的:
我们先将整个串翻转,后面可以认为是修改右权值
而考虑算法五的过程,对于每个节点
那么时间复杂度即为
算法六
from matthew99, skip2004 and mayaohua
这里有另外一个角度:我们不从后缀树的角度,而是从自动机的角度考虑。
为了方便讨论,我们不翻转字符串,还是修改左权值
然后我们考虑直接建出正串的 SAM ,这是一个 DAG 。按照 SAM 自身的性质,我们如果固定左端点
这是一个 DAG 上路径求和的问题,看起来很不可做?
利用一下 SAM 自身的特殊性质:这是一个
有了这个结构,我们做这个问题就很简单了:类似树上的重链剖分,每次从根节点开始,跳链求和即可。对于不在链上的转移边,我们可以直接知道走哪条,但在一条链上我们需要知道走多少条边,可以发现这只需要知道当前的
那么,总时间复杂度即为
值得一提的是,如果用算法七的角度来看,算法六其实就是对正串后缀树进行了重链剖分,这显然是多此一举的。至少在这个问题上, DAG 剖分的思想并没有带来更优秀的复杂度。
算法七
from mayaohua
如果把算法五的正反串对应思想,和算法六的自动机结合起来,能得到什么呢?
我们考虑分别建出正串 SAM (反串后缀树) 和正串后缀树(反串 SAM)。
考虑原串的每个子串,它在正串 SAM 上对应一个节点,在正串后缀树上对应另一个节点。那么考虑正串后缀树上的某个节点
引理:对
证明:显然
这给出了一个非常简单的算法:同算法六一样考虑计算
这样就得到了一个非常简单的
这个算法的扩展性非常强,修改贡献函数或是支持对单侧权值的复杂修改都不是问题(可能需要结合一些正串后缀树上的处理算法)。我们在 DFS 的过程中,其实就是在每个节点处找到了算法五中所求的在另一边后缀树上的定位,但这里不需要差分,因此即使贡献函数不可减,也能非常完美的解决。
同时,这里我们事实上把正串 SAM 上非后缀节点,且出度为
校验码
from command_block,数据、标程、题解 by command_block
为了方便,下文默认
算法一
使用筛法求出
复杂度
算法二
解决
熟练的选手会使用各种筛法或 powerful numbers 完成本部分分。与正解无关故不展开介绍。
- 观察:
现求
- 设
由于涉及到的
现在答案是
对
当
当
那么每段只需要求
那么
这部分复杂度
算法三
同样考虑提取
令
设
为了避免混淆,下面一律用
考虑常见问题:对于一个数论函数
先求出
考虑预处理至
其余部分整除分块计算,复杂度为
对于
我们递推计算其余的
注意到转移中需要枚举约数,由于所有的
粗略的复杂度估界:
整除起始点为
当
由于
单次转移的复杂度有显然的上界
于是总时间得到了一个粗略的上界
实际上,当
除了此部分递推外的时间是
期望得分:
算法四
from rushcheyo
约定
下面我们考虑在枚举的时候避开最大质因子。假如现在枚举到了质数
上面这段做法有个名字:Min_25 筛。DP 预处理的部分复杂度是
算法五
from ilnil
见 https://ilnil.blog.uoj.ac/blog/6538 。
卫星基站建设
from command_block,数据、标程、题解 by command_block
为了避免细节,我们给所有的点加上随机扰动,那么就不会出现三点共线,三线交于一点等等情况了。
算法一
暴力枚举卫星集合
若两者的交都不为空,则从交区域中分别取一点建立基站。否则必然不可能完整收集。
将能够完整收集的方案中对应的“主星”计入答案。
复杂度
算法二
我们发现,卫星集合的个数虽然很多,实际能够连在同一个基站中的却很少。
可以把三角形描述为三个半平面的交集,点在三角形内等价于点同时在三个半平面内。
设集合
若

于是,只有
怎么找到这些集合呢?
求出分界线的所有
对于相交的两条直线,与交点相邻的有
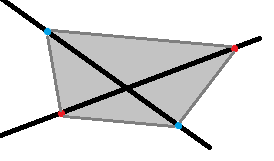
这样能够保证每个区域内至少被取到一个点,正确性较显然。
对于每个点,分别求出它的
接下来问题可以视作 : 给出一些集合,找出两个集合的并集等于全集。
那么,可以枚举两个集合计算并集,若使用位运算优化,复杂度可视作
在 unsigned long long 压位。
期望得分
算法三
不难发现方案中两个基站的地位是相同的。可以只统计
对于某个
若有交集则表示集合
复杂度为
算法四
性质 1
对于平面划分中的一个区域,与其相邻的区域的
我们可以按照某种顺序依次在相邻的区域之间移动,这样每次只会有最多一个碎片进出当前的
下面利用性质 1来快速求出每个区域的
像沿着墙壁摸一样找出各个区域的边界,如图:
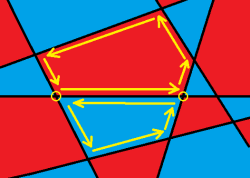
实现细节上,需要记录每个交点是由那条直线产生的,还要记录反映射等等。
建立对偶图,区域用点表示,相邻的区域之间连边,边上记录变化的半平面。
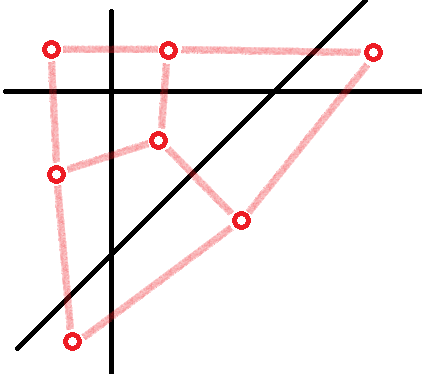
对该图进行遍历即可求出每个区域的
标程使用了堆顺便求出每个点
如果只利用性质 1 ,可以将问题转化成同时带有加入和删除的半平面交问题。
可以采用线段树分治配合数据结构(李超树等)维护,复杂度至少为
这里有一个剪枝:不被任何三角形覆盖的区域不求解,相邻的
性质 2
在对偶图中距离某点
(粗略的)证明:不妨令起点连通块过原点,一条直线是
考虑和
任意一个连通块只要包含这
这已经产生了
实现:一个三角形的进出会导致
无进出的边连接的区域是等价的,不必处理多次,边权也可视为
每次随机选取未被覆盖的一个点,并覆盖周围
复杂度正确性留给读者思考。
考虑选定一个阈值
对于每个关键点,进行一定的预处理之后,可以回答距离自己
经过的
在
预处理时,对于每层凸包,分别对每个关键位记下被哪条直线覆盖,这样可以
这样,预处理一次的复杂度是
现在我们需要对历经过
求值时,若当前层凸壳上对应的直线被删去了,则查找未被删除的前驱后继更新答案,并进入下一层。
对于散着加入的
一次求值的复杂度显然是
实现时,可以懒处理,第一次问到某层才预处理该层,可以有效减小常数。
最后,把二分出来的相邻两个关键位求值时牵涉到的直线,和新加入的所有直线求半平面交,看看是否为空即可。
这部分直线是
取
由于数据规模和小常数,本算法表现优异。具体代码实现较为繁琐。
期望得分



 鄂公网安备 42010202000505 号
鄂公网安备 42010202000505 号