
如果本题评测出现问题,请联系管理员。
新加坡的互联网主干网由
一个由互不相同的站点所组成的站点序列
任意站点
- 执行路由函数,找到
- 将数据包转发给这个邻居。
然而,站点有存储内存限制,可能无法存下路由函数中需要使用的完整的主干网链路列表。
你的任务是实现主干网的路由机制,它由两个函数组成:
- 第一个函数的输入参数为
- 第二个函数是路由函数,它在站点编号分配好后部署到所有站点上。
- 它的输入参数如下:
- 该函数应该返回一个
- 它的输入参数如下:
在每个子任务中,你的得分取决于所有站点被分配到的编号的最大值(通常来说,编号最大值越小越好)。
实现细节
你必须引用 stations.h 头文件。
你需要实现下列函数:
int[] label(int n, int k, int[] u, int[] v)- 该函数应该返回一个大小为
int find_next_station(int s, int t, int[] c)- 该函数应该返回一个
每个测试用例包含一个或多个独立的场景(也就是不同的主干网描述)。对于一个包含
程序第一次运行期间:
label函数被调用返回的编号将被评测系统保存,并且
find_next_station不会被调用。
程序第二次运行期间:
find_next_station会被调用若干次。对于每次调用,评测程序会选择任意某个场景,该场景中的label函数所返回的编号方式将用于本次find_next_station调用。label不会被调用。
特别地,在评测程序第一次运行期间,保存在静态或全局变量中的信息将无法在 find_next_station 函数中使用。
例子
考虑下列调用:
label(5, 10, [0, 1, 1, 2], [1, 2, 3, 4])共有
为了返回下列编号方案:
| 序号 | 编号 |
|---|---|
| 0 | 6 |
| 1 | 2 |
| 2 | 9 |
| 3 | 3 |
| 4 | 7 |
函数 label 应该返回
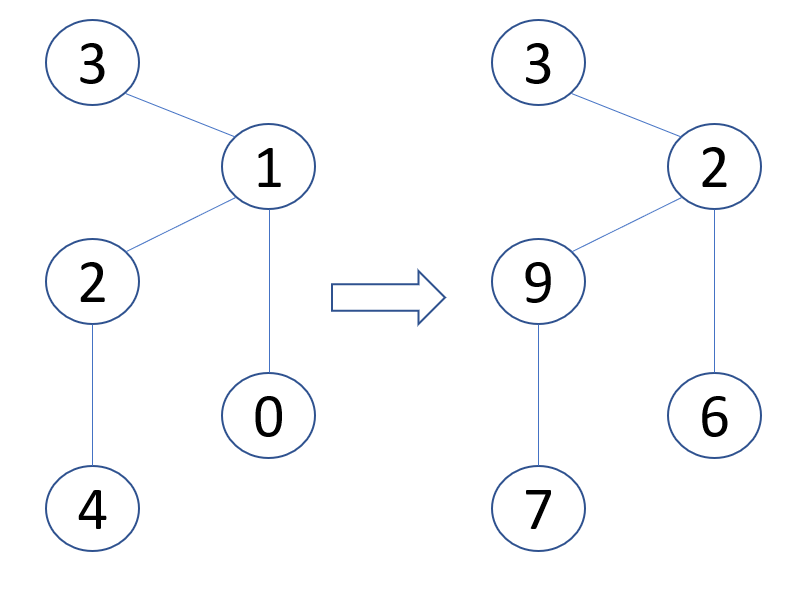
假设编号按照上图所示进行分配,考虑下列的调用:
find_next_station(9, 6, [2, 7])它表示数据包当前所处的站点编号为
站点编号依次为
考虑另一个可能的调用:
find_next_station(2, 3, [3, 6, 9])该函数应该返回
约束条件
对于 label 的每次调用:
对于 find_next_station 的每次调用,其输入参数来自于任意选择的某次之前对 label 的调用。
考虑它所产生的编号,
对于每个测试用例,所有场景加到一起,传递给函数 find_next_station 的所有数组
子任务
- (5分)
- (8分)
- (16分)
- (10分)
- (61分)
在子任务 5 中,你可以获得部分分。 令 label 返回的最大编号。 对于这个子任务,你的得分将根据下表计算得到:
| 最大编号 | 得分 |
|---|---|
评测程序示例
评测程序示例以如下格式读取输入数据:
- 第
接下来是
- 第
- 第
- 第
find_next_station的调用次数 - 第
find_next_station时所涉及的站点的序号。此时,数据包在站点
评测程序示例以如下格式打印你的结果:
- 第
接下来是
- 第
find_next_station时返回的结果。
注意:评测程序示例每次执行时会同时调用 label 和 find_next_station。
hack
在 hack 时,数据格式与上述类似,但是您需要在最后额外添加一行两个数,第一个数为 0/1,表示是否给予部分分,第二个数为
限制与约定
时间限制:
空间限制:
 鄂公网安备 42010202000505 号
鄂公网安备 42010202000505 号